Abstract: This document provides general information about the
Kannada language and conventions of its usage in computers. It provides
information about the Input, Storage, Display and Printing of Kannada Characters.
We strongly feel that this information gathered from various standards is
necessary for the correct usage of the language in various applications of
Kannada Language Computing. It also includes the sorting sequence for Kannada
in Unicode.
Note 1: This document contains Unicode characters and can be viewed using MS Office XP on Windows XP or equivalent
Note 2: The
Convention followed in Unicode (Version 3.0) Chapter 9 (South and Southeast
Asian Scripts) is used in this document and might differ from the notation
commonly used in the Kannada Script.
Contact Information:
Chief Investigator
Resource Centre for Indian Language Technology
Solutions- Kannada
Department of Management Studies
Indian Institute of Science
Phone : 91-80-346
6022 / 394 2377 (Dir)
91-80-394 2378 / 394 2567
Fax :
91-80-346 6022 / 3600683 / 3600085
Email : root@iltwebserver.mgmt.iisc.ernet.in
Table
of Contents
1. History of Kannada Language 5
1.1 Description of Kannada Language 5
1.2 Brief introduction to Kannada language 6
1.2.1 Vowels 6
1.2.2 Anuswaras 6
1.2.3 Visarga 6
1.2.4 Avagraha 6
1.2.5 Consonants 6
1.2.6 Basic Language Rule in Kannada 7
2. Technical Characteristics 9
2.1
Kannada Alphabet Characteristic 9
2.1.1 Consonant Letters 9
2.1.2 Independent Vowel Letters 9
2.1.3 Dependent Vowel Signs 9
2.1.4 Virama (Halant) 11
2.1.5 Consonant Conjuncts 11
2.1.6 Visarg 12
2.1.7 Avagrah 12
2.1.8 Numerals 12
2.1.9 Punctuation Marks 12
2.1.10 Ancient Signs 12
2.2 Fonts 12
2.2.1 Font developing Tools 12
2.3 Keyboard 13
2.4 Presentation and
Storage Considerations 14
2.5 Rendering Rules 14
2.5.1 Dead Consonant Rule 15
2.5.2 Consonant RA Rules 15
2.5.3 Ligature Rules 16
2.6 Sorting issues in
Kannada 17
2.6.1 Sorting of Nukta
characters 17
2.6.2 Sorting the data records
containing anuswara and visarga 17
2.6.3 Sorting of words with dead
consonants 18
2.6.4 Sorting of Conjuncts having two
different display forms 19
2.6.5 Sorting of Diacritic characters 19
2.6.6 Conclusion 19
3. References 20
Appendix 1: Unicode chart and the Collation chart if
deletion and relocation are not allowed 21
Appendix 2: Unicode chart and the Collation chart if deletion and relocation are allowed 24
Appendix 3: Output from FontLab displaying all glyphs in the glyph
set standardised by KGP 27
1. History of
Kannada Language
Kannada is a south Indian language
spoken in Karnataka state of India.Kannada is originated from the Dravidian
Language. Telugu, Tamil, Malayalam are the other South Indian Languages
originated from Dravidian Language. Kannada and Telugu have almost the same
script. Malayalam and Tamil have resemblance. Kannada as a language has
undergone modifications since BCs. It can be classified into four types-
Purva Halegannada (from the
beginning till 10th Century)
Halegannada (from 10th
Century to 12th Century)
Nadugannada (from 12th
Century to 15th Century)
Hosagannada (from 15th
Century)
1.1 Description of Kannada Script
Kannada script is the visual form of
Kannada language. It originated from southern Bramhi lipi of Ashoka period. It underwent
modifications periodically in the reign of Sathavahanas, Kadambas, Gangas,
Rastrakutas, and Hoysalas. Even before seventh-Century, the
Telugu-Kannada script was used in the inscriptions of the Kadambas of Banavasi
and the early Chalukya of Badami in the west. From the middle of the seventh
century the archaic variety of the Telugu-Kannada script developed a middle
variety. The modern Kannada and Telugu scripts emerged in the thirteenth
Century. Kannada script is also used to write Tulu, Konkani and Kodava
languages.
Kannada along with other Indian language scripts shares a large number
of structural features. The writing system of Kannada script encompasses the
principles governing the phonetics and a syllabic writing systems, and phonemic
writing systems (alphabets). The effective unit of writing Kannada is the
orthographic syllable consisting of a consonant and vowel (CV) core and
optionally, one or more preceding consonants, with a canonical structure
of ((C) C) CV. The orthographic
syllable need not correspond exactly with a phonological syllable, especially
when a consonant cluster is involved, but the writing system is built on
phonological principles and tends to correspond quite closely to pronunciation.
The orthographic syllable is built up of alphabetic pieces, the actual letters
of Kannada script. These consist of distinct character types: Consonant
letters, independent vowels and the corresponding dependent vowel signs. In a
text sequence, these characters are stored in logical phonetic order.
The Kannada block of Unicode Standard (0C80 to 0CFF) is based on
ISCII-1988 (Indian Standard Code for Information Interchange). The Unicode
Standard (Version 3) encodes Kannada characters in the same relative positions
as those coded in the ISCII-1988 standard.
1.2 Brief introduction to
Kannada language
1.2.1 Vowels (Swaras) Vowels are the
independently existing letters which are called Swaras. They are-
ಅ ಆ ಇ ಈ ಉ ಊ ಋ ಎ ಏ ಐ ಒ ಓ ಔ
There are two types of Swaras depending on the time used to pronounce.
They are Hrasva Swara and Deerga Swara.
A freely existing independent vowel which can be pronounced
in a single matra time (matra kala) also called as a matra. They are-
ಅ ಇ ಉ ಋ ಎ ಐ ಒ ಔ
Deergha Swara A freely existing independent vowel which can be pronounced
in two matras. They are-
ಆ ಈ ಊ ಏ ಓ
1.2.2 Anuswaras ಅಂ
1.2.3 Visarga ಅಃ
1.2.4 Avagraha Also called as Plutha, which is used for the third matra
either in a consonant or a vowel.
1.2.5 Consonants (Vyanjanas) These
are dependent on vowels to take a independent form of the Consonant. These can
be divided into Vargeeya and Avargeeya.
Vargeeya Vyanjanas
ಕ್ ಖ್
ಗ್ ಘ್ ಙ್
ಚ್ ಛ್
ಜ್ ಝ್ ಞ್
ತ್ ಥ್
ದ್ ಧ್ ನ್
ಟ್ ಠ್
ಡ್ ಢ್ ಣ್
ಪ್ ಫ್
ಬ್ ಭ್ ಮ್
Avargeeya Vyanjanas
ಯ್ ರ್
ಲ್ ವ್ ಶ್ ಷ್ ಸ್ ಹ್
ಳ್
1.2.6 Basic Language Rule in Kannada
When a
dependent consonant combines with an independent vowel, a
Akshara is
formed.
Consonant (Vyanjana) + Vowel (matra) ---> Letter (Akshara)
Example: ಕ್ + ಅ ---> ಕ
Based on
this rule we can combine all the Consonants (Vyanjanas) with the existing Vowels
(matra)
to form Kagunitha for Kannada alphabet.
ಕ ಕಾ
ಕಿ ಕೀ ಕು ಕೂ ಕೃ ಕೆ
ಕೇ ಕೈ ಕೊ ಕೋ ಕೌ ಕಂ
ಕಃ
ಖ ಖಾ
ಖಿ ಖೀ ಖು ಖೂ ಖೃ ಖೆ
ಖೇ ಖೈ ಖೊ ಖೋ ಖೌ ಖಂ
ಖಃ
ಗ ಗಾ
ಗಿ ಗೀ ಗು ಗೂ ಗೃ ಗೆ
ಗೇ ಗೈ ಗೊ ಗೋ ಗೌ ಗಂ
ಗಃ
ಘ ಘಾ
ಘಿ ಘೀ ಘೃ ಘೆ ಘೇ ಘೈ
ಘೊ ಘೊ ಘೋ ಘೌ ಘಂ ಘಃ
ಙ ಙಾ
ಙಿ ಙೀ ಙು ಙೂ ಙೃ ಙೆ
ಙೇ ಙೈ ಙೊ ಙೋ ಙೌ ಙಂ
ಙಃ
ಚ ಚಾ
ಚಿ ಚೀ ಚು ಚೂ ಚೃ ಚೆ
ಚೇ ಚೈ ಚೊ ಚೋ ಚೌ ಚಂ
ಚಃ
ಛಾ ಛಿ
ಛೀ ಛು ಛೂ ಛೃ ಛೆ ಛೇ
ಛೈ ಛೊ ಛೋ ಛೌ ಛಂ ಛಃ
ಜ ಜಾ
ಜಿ ಜೀ ಜು ಜೂ ಜೃ ಜೆ
ಜೇ ಜೈ ಜೊ ಜೋ ಜೌ ಜಂ
ಜಃ
ಝ ಝಾ
ಝಿ ಝೀ ಝು ಝೂ ಝೃ ಝೆ
ಝೇ ಝೈ ಝೊ ಝೋ ಝೌ ಝಂ
ಝಃ
ಞ ಞಾ
ಞಿ ಞೀ ಞು ಞೂ ಞೃ ಞೆ
ಞೇ ಞೈ ಞೊ ಞೋ ಞೌ ಞಂ
ಞಃ
ತ ತಾ
ತಿ ತೀ ತು ತೂ ತೃ ತೆ
ತೇ ತೈ ತೊ ತೋ ತೌ ತಂ
ತಃ
ಥ ಥಾ
ಥಿ ಥೀ ಥು ಥೂ ಥೃ ಥೆ
ಥೇ ಥೈ ಥೊ ಥೋ ಥೌ ಥಂ
ಥಃ
ದ ದಾ
ದಿ ದೀ ದು ದೂ ದೃ ದೆ
ದೇ ದೈ ದೊ ದೋ ದೌ ದಂ
ದಃ
ಧ ಧಾ
ಧಿ ಧೀ ಧು ಧೂ ಧೃ ಧೆ
ಧೇ ಧೈ ಧೊ ಧೋ ಧೌ ಧಂ
ಧಃ
ನ ನಾ
ನಿ ನೀ ನು ನೂ ನೃ ನೆ
ನೇ ನೈ ನೊ ನೋ ನೌ ನಂ
ನಃ
ಟ ಟಾ
ಟಿ ಟೀ ಟು ಟೂ ಟೃ ಟೆ
ಟೇ ಟೈ ಟೊ ಟೋ ಟೌ ಟಂ
ಟಃ
ಠ ಠಾ
ಠಿ ಠೀ ಠು ಠೂ ಠೃ ಠೆ
ಠೇ ಠೈ ಠೊ ಠೋ ಠೌ ಠಂ
ಠಃ
ಡ ಡಾ
ಡಿ ಡೀ ಡು ಡೂ ಡೃ ಡೆ
ಡೇ ಡೈ ಡೊ ಡೋ ಡೌ ಡಂ
ಡಃ
ಡ ಢಾ
ಢಿ ಢೀ ಢು ಢೂ ಢೃ ಢೆ
ಢೇ ಢೈ ಢೊ ಢೋ ಢೌ ಢಂ
ಢಃ
ಣ ಣಾ
ಣಿ ಣೀ ಣು ಣೂ ಣೃ ಣೆ
ಣೇ ಣೈ ಣೊ ಣೋ ಣೌ ಣಂ
ಣಃ
ಪ ಪಾ
ಪಿ ಪೀ ಪು ಪೂ ಪೃ ಪೆ
ಪೇ ಪೈ ಪೊ ಪೋ ಪೌ ಪಂ
ಪಃ
ಫ ಫಾ
ಫಿ ಫೀ ಫು ಫೂ ಫೃ ಫೆ
ಫೇ ಫೈ ಫೊ ಫೋ ಫೌ ಫಂ
ಫಃ
ಬ ಬಾ
ಬಿ ಬೀ ಬು ಬೂ ಬೃ ಬೆ
ಬೇ ಬೈ ಬೊ ಬೋ ಬೌ ಬಂ
ಬಃ
ಭ ಭಾ
ಭಿ ಭೀ ಭು ಭೂ ಭೃ ಭೆ
ಭೇ ಭೈ ಭೊ ಭೋ ಭೌ ಭಂ
ಭಃ
ಮ ಮಾ
ಮಿ ಮೀ ಮು ಮೂ ಮೃ ಮೆ
ಮೇ ಮೈ ಮೊ ಮೋ ಮೌ ಮಂ
ಮಃ
ಯ ಯಾ
ಯಿ ಯೀ ಯು ಯೂ ಯೃ ಯೆ
ಯೇ ಯೈ ಯೊ ಯೋ ಯೌ ಯಂ
ಯಃ
ರ ರಾ
ರಿ ರೀ ರು ರೂ ರೃ ರೆ
ರೇ ರೈ ರೊ ರೋ ರೌ ರಂ
ರಃ
ಲ ಲಾ
ಲಿ ಲೀ ಲು ಲೂ ಲೃ ಲೆ
ಲೇ ಲೈ ಲೊ ಲೋ ಲೌ ಲಂ
ಲಃ
ವ ವಾ
ವಿ ವೀ ವು ವೂ ವೃ ವೆ
ವೇ ವೈ ವೊ ವೋ ವೌ ವಂ
ವಃ
ಶ ಶಾ
ಶಿ ಶೀ ಶು ಶೂ ಶೃ ಶೆ
ಶೇ ಶೈ ಶೊ ಶೋ ಶೌ ಶಂ
ಶಃ
ಷ ಷಾ
ಷಿ ಷೀ ಷು ಷೂ ಷೃ ಷೆ
ಷೇ ಷೈ ಷೊ ಷೋ ಷೌ
ಸ ಸಾ
ಸಿ ಸೀ ಸು ಸೂ ಸೃ ಸೆ
ಸೇ ಸೈ ಸೊ ಸೋ ಸೌ ಸಂ
ಸಃ
ಹ ಹಾ
ಹಿ ಹೀ ಹು ಹೂ ಹೃ ಹೆ
ಹೇ ಹೈ ಹೊ ಹೋ ಹೌ ಹಂ
ಹಃ
ಳ ಳಾ
ಳಿ ಳೀ ಳು ಳೂ ಳೃ ಳೆ
ಳೇ ಳೈ ಳೊ ಳೋ ಳೌ ಳಂ
ಳಃ
2. Technical Characteristics
Note: The
Convention followed from this section of the document is same as the Unicode
Chapter 9 (South and Southeast Asian Scripts) and might not be grammatically
correct.
2.1 Kannada Alphabet Characteristic
2.1.2 Consonant
Letters
Each of the consonant represents a single
consonantal sound but also has the peculiarity of having inherent vowel,
generally the short vowel ಅ (U+0C85). Thus, U+0C95 Kannada
letter KA represents not just K (ಕ್) but KA (ಕ). In the presence of
the dependent vowel, however, the inherent vowel associated with a consonant
letter is overridden by the dependent vowel. The different Consonants in
Kannada are:
ಕ ಖ ಗ ಘ ಙ
ಚ ಛ ಜ ಝ ಞ
ತ ಥ ದ ಧ ನ
ಟ ಠ ಡ ಢ ಣ
ಪ ಫ ಬ ಭ ಮ
ಯ ರ ಲ ವ
ಶ ಷ ಸ ಹ ಳ
2.1.3 Dependent Vowel Signs (Matras)
The dependent vowels, also known as Swaras
in Kannada, serve as the common manner of writing non-inherent vowels and are
generally referred to as Swara Chinhas in Kannada or Matras in Sanskrit.
The dependent vowels do not appear stand-alone; rather, they are visibly
depicted in combination with a base-letter form (generally a consonant). A
single consonant or a consonant cluster may have a dependent vowel applied to
it to indicate the vowel quality of the syllable, when it is different from the
inherent vowel. Explicit appearance of a dependent vowel in a syllable
overrides the inherent vowel ಆ (U +0C85) of a single consonant
letter.
There are several variations with which the
dependent vowels are applied to the base letterforms. Most of them appear as
non-spacing dependent vowels signs when applied to base letterforms; above to
the right side of a consonant letter or a consonant cluster. The following are
the exceptions and variations for the above rule:
·
The two dependent
vowel signs (U+0CCC3 & U+0CC4) appear one level below and to the right of
the consonant or the consonant cluster, separated by a small white space.
·
Each of the five
dependent vowels (U+0CC0, U+0CC7, U+0CC8, U+0CCA & U+0CCB) are
depicted by two or three glyph
components (two part or three part vowel signs ) with one component appearing
with a space to the right of the consonant or the consonant cluster.
i) In the case o f three the above-mentioned
two/three-part dependent vowels (at U+0CC0, U+0CC7, U+0CCB), the non-spacing
components of each of them is (are) the same as the vowel sign(s) of the
corresponding preceding short vowels. The spacing component for each of these
dependent vowels is the same ‘length mark U+0CD5 given in Unicode version 3.
The logic for this is that these dependent vowels are nothing but the long
forms (independent and phonetically distinct) of the preceding short vowels.
ii) The first component of the
dependent vowel (U+0CC8) mentioned above, is the same as the dependent vowel (ೆ, U+0CC6) with the second component (U+0CD6) defined independently in
Unicode version 3. The second part appears slightly below and to the right of
the consonant or the consonant clusters.
·
In view of this, it is
important to note that the two glyphs (the length mark and the second component
of ೈ) represent with the codes at U+0CD5 and U+0CD6 in Unicode version 3 have no
independent existence and do not play any part as independent codes in the
collation algorithm.
·
Unlike Devanagari, the
Kannada script does not have any character with a left-side dependent vowel
sign.
·
A one-to-one
correspondence exists between independent vowels and dependent vowel signs.
The Matras are-
2.1.4 Virama (Halant)
Like Devanagari, Kannada script also employs a sign
known as Halant or vowel omission sign. A halant sign (್, U+0CCD) nominally serves
to cancel (or kill) the inherent vowel of the consonant to which it is applied.
It functions as a combining character. When a consonant has lost its inherent
vowel by the application of halant, it is known as a dead consonant. The
dead consonants are the presentation forms used to depict the consonants
without an inherent vowel. Their rendered forms in Kannada resemble the full
consonant with vertical stem replaced by the halant sign, which marks a
character core. The stem glyph (U+0CBB) is graphically and historically related
to the sign denoting the inherent /a/ (ಅ) vowel (U+0C85). In contrast, a live consonant is
a consonant that retains its inherent vowel or is written with an explicit
dependent vowel sign. The dead consonant is defined as a sequence consisting of
a consonant letter followed by a halant. The default rendering for a
dead consonant is to position the halant as a combining mark bound to
the consonant letterform. The Halant in Kannada is ್
Like any other Indian script, Kannada is also noted
for a large number of consonant conjunct forms that serve as orthographic
abbreviations (ligatures) of two or more adjacent forms. This abbreviation
takes place only in the context of a consonant cluster. An orthographic consonant
cluster is defined as a sequence of characters that represent one or more dead
consonants (denoted by Cd) followed by a normal live consonant
(denoted by Cl).
Corresponding to each Kannada consonant, there exists a separate and unique glyph, which is specially used
to represent the corresponding consonant in a consonant cluster. Most of these
conjunct consonant glyphs resemble their original consonant forms (many without
the implicit vowel sign, wherever applicable).
In Kannada,
there is only one type of conjunct formation (consonant cluster) and it is
depicted as follows:
·
The first consonant of
the consonant cluster is rendered with the implicit or a different dependant
vowel appearing as the terminal element of the consonant cluster.
·
The remaining consonants
(consonants in between the first consonant and the terminal vowel element)
appear in conjunct consonant glyph forms in the phonetic order. They are
generally depicted directly below or sometimes below but to the right of the
first consonant.
Thus, the systematically designed Kannada script
font contains the conjunct glyph components, but they are not encoded as
Unicode characters, because they are the resultant of ligation of distinct
letters. Kannada script rendering software must be able to map appropriate
combinations of characters in context to the appropriate conjunct glyphs in
fonts.
Comes after a vowel sound and represents a sound
similar to /h/.
Avagraha sign is a spacing mark used while rendering
Sanskrit text. This is located at U+0CBD.
Kannada numerals are located from U+0CE6 to U+0CEF
All Punctuation mark in
Kannada is borrowed from English.
These characters are not included in the range for
Kannada in the Unicode Character set.
Some of he Halegannada characters are placed at
U+0C8C, U+0CB1, U+0CE1.
2.2
Fonts
There are a number of TrueType
fonts available for Kannada among which some of them follow an encoding
standard (like ISCII) and others do not follow any encoding standard and is
tied to a proprietary encoding. The Kannada Ganaka Parishat has standardised
the glyph set to be used by all the Software that support Kannada. Annexure-1
displays the glyphs standardised by KGP. Microsoft has released an OpenType
font (with TrueType outlines) for Kannada – “Tunga.ttf” that follows Unicode as its encoding
standard.
The OpenType
font format is an extension of the TrueType font format, adding support for
PostScript font data. The following tools can be used for designing of the
OpenType Font.
- FontLab version 4.0 (A trial version for Windows is available for download at http://www.fontlab.com/html/fontlab.html#downloads)
- Font Creator Program version 3.0 (A trial version is
available for download at http://www.high-logic.com/download.htm)
- Fontographer version 4.1 (No trial version is available. For more
information - http://www.macromedia.com/software/fontographer/)
- Microsoft Visual OpenType Layout Tool "VOLT" provides an easy-to-use
graphical user interface to add OpenType layout tables to fonts with
TrueType outlines. It is licensed free and can be downloaded from the
online community http://communities.msn.com/MicrosoftVOLTuserscommunity
2.3 Keyboard
Inputting Kannada or any other Indian language
needs Keyboard driver / Input Method, which is a Software Component that
interprets user operations such as typing keys. There are many Keyboard
Drivers/Input Methods available in the market for Windows Operating Systems
like Baraha, Sreelipi, Akruthi, Kalitha etc. They follow different encoding
methods (glyph codes) and support different keyboard layouts like INSCRIPT,
English Phonetic, Typewriter 1, and Typewriter 2.
Microsoft supports Input Methods for nine Indian
languages (including Kannada) in Office XP on Windows XP with INSCRIPT keyboard
layout, which is common to all Indian languages and uses Unicode as the
encoding Standard.
Government of Karnataka (Kannada Ganaka Parishat)
has proposed a Standard Keyboard layout for Kannada. In this layout only 26
keys which are painted with English characters on a Keyboard can be used to
represent 51 basic alphabets and special symbols in Kannada (13 swaras, 34
consonants and 4 special symbols). This is possible as each key has a dual
function of representing the small case (normal key) and Capital case (Shift
key) letters in English, as shown in the figure 2.1
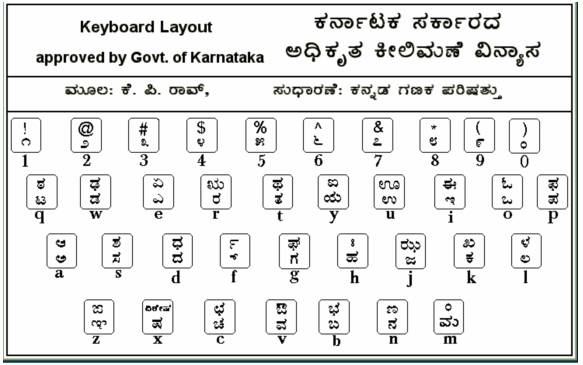
Fig. 2.1: Keyboard Layout proposed
by Kannada Ganaka Parishath.
Since the 51 keys have
been used while the keyboard provides 52 possibilities, that option (key X is
not assigned) can be used to represent foreign sounds such as combination of
Nukta and ಫ. Besides, there is a need to represent the old ಱ. The combination of X with consonant ರ yields ಱ.
2.4 Presentation and Storage
Considerations
The order for storage of plain text in Kannada
generally follows the phonetic order, that is, a CV syllable with a dependant
vowel is always encoded as a consonant letter C followed by a vowel sign V in
the memory representation. This order is employed by the ISCII standard and
corresponds with phonetic and keying order of textual data. Unlike Devanagari
and some other Indian scripts, all the dependent vowels in Kannada are depicted
to the right of their consonant letters. Hence there is no need to reorder the
elements in mapping from the logical (character) store to the presentation
(glyph) rendering and vice versa.
Character order Glyph
order
KA
+
I KA + I
ಕ + ಇ ಕಿ
Further, Kannada script does not
allow half-consonants, ligatures and half ligature forms.
2.5 Rendering Rules
(Based on Microsoft Uniscribe-OpenType implementation of the UNICODE
Rendering Rules)
2.5.1 Notation. In the next set of rules, the following notation applies:
Cn Nominal glyph form of a
consonant C as it appears in the code charts.
Cl A live consonant, depicted
identically to Cn.
Cd Glyph depicting
the dead consonant form of a consonant C.
Ch Glyph depicting
the half-consonant form of a consonant C.
Ln Nominal
glyph form of a conjunct ligature consisting of two or more component
consonants. A conjunct ligature composed of two
consonants X and Y is also denoted by X.Yn.
RAsub A non-spacing combining mark
glyph form positioned below the base glyph form.
Vvs Glyph depicting the dependent
vowel sign form of a vowel V.
Viraman The nominal glyph form non-spacing
combining mark depicting U+0CCD Kannada sign Virama.
A virama character is not always depicted; when it
is depicted, it adopts this non-spacing mark form.
2.5.1 Dead Consonant
Rule. The following rule logically precedes the application of any other rule to
form a dead consonant. Once formed, a dead consonant may be subject to other
rules described next.
R0: When a consonant Cn precedes a VIRAMAn, it is
considered to be a dead consonant Cd. A consonant Cn that
does not precede VIRAMAn is considered to be live consonant Cl.
![]() TAn + VIRAMAn TAd
TAn + VIRAMAn TAd
![]() ತ + ್ ತ್
ತ + ್ ತ್
(Based on
Microsoft Uniscribe-OpenType implementation of the UNICODE Rendering Rules)
2.5.2 Consonant RA Rules:
R1: If the dead consonant RAd precedes either a consonant or
an independent vowel, then it is replaced by the postscript ARKAVATTU,
which is positioned so that it applies to the logically subsequent element in
the memory representation.
![]() RAd + KAl KAl
+ ARKAVATTU Displayed Output
RAd + KAl KAl
+ ARKAVATTU Displayed Output
![]() ರ್ + ಕ ಕ
+ARKAVATTU ರ್ಕ
ರ್ + ಕ ಕ
+ARKAVATTU ರ್ಕ
R2: Except for the dead consonant RAd, when a dead consonant Cd
precedes the live consonant RAl, then Cd is
replaced with its nominal form Cn ,
and RA is replaced by the subscript non-spacing mark RAsub
, which is positioned so that it applies to Cn.
![]() THAd + RAl THAn + RAsub Displayed Output
THAd + RAl THAn + RAsub Displayed Output
![]()
![]() ಠ್ + ರ ಠ + RAsub ಠ್ರ
ಠ್ + ರ ಠ + RAsub ಠ್ರ
R3: If a dead consonant (other than RAd) precedes RAd,
then the substitution of RA for RAsub is performed as
described above; however, the VIRAMA that formed RAd remains
so as to form a dead consonant conjunct form. A dead consonant conjunct form
that contains an absorbed RAd may subsequently combine to
form a multipart conjunct form.
![]()
![]() TAd + RAd TAn + RAsub +
VIRAMAn T.RAd
TAd + RAd TAn + RAsub +
VIRAMAn T.RAd
![]()
![]() ತ್ + ರ್ ತ + RAsub + ್ ತ್ರ್
ತ್ + ರ್ ತ + RAsub + ್ ತ್ರ್
A dead consonant conjunct form that contains an
absorbed RAd may subsequently combine to form a multipart conjunct
form.
![]() T.RAd
+ YAl T.R.YAn
T.RAd
+ YAl T.R.YAn
![]() ತ್ರ್ + ಯ ತ್ರ್ಯ
ತ್ರ್ + ಯ ತ್ರ್ಯ
Ligature Rules: Subsequent to the application of the rules
just described, a set of rules governing ligature formation apply. The precise
application of these rules depends on the availability of glyphs in the current
font(s) being used to display text.
R4: If a dead consonant immediately precedes another dead consonant or a live
consonant, then the first dead consonant may join the subsequent element to
form a twopart conjunct ligature form.
![]() JAd
+ NYAl J.NYAn
JAd
+ NYAl J.NYAn
![]() ಜ್ + ಞ ಜ್ಞ
ಜ್ + ಞ ಜ್ಞ
R5: A conjunct ligature form can itself behave as a dead consonant and enter
into further, more complex ligatures.
![]() SAd + TAd
+ KAl S.T.KAn
SAd + TAd
+ KAl S.T.KAn
![]() ಸ್ + ತ್ + ಕ ಸ್ತ್ಕ
ಸ್ + ತ್ + ಕ ಸ್ತ್ಕ
R6: If a nominal consonant or conjunct ligature form precedes RAsub
as a result of the application of rule R2, then the consonant or
ligature form may join with RAsub to form a multipart
conjunct ligature (see rule R2 for more information).
![]() KAl
+ RAd K.RAn
KAl
+ RAd K.RAn
![]() ಕ + ರ್
ಕ್ರ
ಕ + ರ್
ಕ್ರ
R7: In some cases, other combining marks will also combine with a base
consonant, either attaching at a nonstandard location or changing shape. In
minimal rendering there are only two cases, RAl with Uvs
or UUvs .
![]()
![]() RAl + Uvs RUn RAl + UUvs RUUn
RAl + Uvs RUn RAl + UUvs RUUn
![]()
![]() ರ + ು ರು
ರ + ೂ ರೂ
ರ + ು ರು
ರ + ೂ ರೂ
R8: When the dependent vowel Ivs is used to override the
inherent vowel of a syllable, it is always written to the extreme left of the
orthographic syllable. If the orthographic syllable contains a consonant
cluster, then this vowel is always depicted to the left of that cluster.
![]() THAd +
RAl + Ivs T.RIn
THAd +
RAl + Ivs T.RIn
![]() ತ್
+ ರ + ಿ
ತ್ರಿ
ತ್
+ ರ + ಿ
ತ್ರಿ
2.6 Sorting issues in Kannada
The sorting sequence for Kannada Unicode is as per
the collation chart given as an annexure. However, the following are some
important issues, which have to be addressed separately for proper sorting of
data in Kannada.
ISCII – 91
provides direct sorting through its codes. It is the natural sorting method just
based on code values. There are no special algorithms for language specific
issues for sorting the data. This results in non-conventional sorting in some
specific cases. The scholars in Kannada have specified the sorting standards in
Kannada. These standards are being followed in all dictionaries and other
documents in Kannada. With this in view, the following four special cases have
been identified.
2.6.1 Sorting of Nukta characters
The
modifying mark or Nukta located at U+0CBC and included in the collation
table is enough to take care of the sorting issues of characters ಜ + (U+0CBC) (modified ಜ) and ಫ + (U+0CBC) (modified ಫ). It also takes care
of any other consonant, which may be modified using Nukta.
2.6.2 Sorting the data records containing anuswara and visarga
In case of sorting a data set containing words
terminating with anuswara, visarga together with other words,
words without terminating dependent vowels are placed in wrong positions.
- Sorting sequence as per the
Unicode is according to the specified standards if the anuswara and
visarga appear within a word.
2.6.3 Sorting of words with dead consonants
- Sorting of words terminating with
dead consonants
Sorting in this case also violates
the sorting rules of Kannada. The Unicode sorting places the word terminating
with the dead consonant at the end of the list. The following list compares the
sorting of a sample data using Unicode table and the acceptable sorting for
this case.
|
Sorted data as per Unicode |
Acceptable sorting |
|
ರಾಕ |
ರಾಕ್ |
|
ರಾಕ್ |
ರಾಕ |
|
ರಾಗ |
ರಾಗ್ |
|
ರಾಗೋ |
ರಾಗ |
|
ರಾಗ್ |
ರಾಗೋ |
- Dead consonants within words
Proper sorting of data with such
words can be achieved by using the invisible zero width consonant just after
the dead consonant.
To circumvent unacceptable situations mentioned in
2.6.2 and 2.6.3 above, the Unicode Standard character U+200C (Zero width
Non-Joiner) can be used appropriately in the preprocessor and collation
algorithms.
2.6.4 Sorting of Conjuncts having two different display forms
Two such
conjuncts are rendered in Kannada at present.
·
Conjuncts with (U+0CB0) as the first consonant
This has been explained at an earlier section as
Consonant RA rules (section 2.5.2)
Words containing both the display forms of the same
consonant cluster with ರ (U+0CB0) as the first consonant
of the cluster had to be sorted as follows. Even though the display rendering
are different, both are identical in all respects. It is therefore natural that
they should appear at consecutive positions. Even though a separate glyph and a
corresponding glyph code are present in the display/storage codes such an
arrangement in Unicode will not render for proper sorting.
The only
alternative is to represent both the display forms by the same set of codes
with a distinguishing code (U+0CF5) within the string for the second display
form. In Unicode form, the distinguishing code value within the string of the
consonant sorting. This can be achieved through preprocessing software, with
specific functions to generate proper glyph codes, storage codes and Unicode at
different levels. Such a situation–specific code representation guarantees
proper sorting of data containing consonant clusters with two different display
forms by ignoring the code U+0CF5 for . This condition has to be incorporated
at the appropriate place in the sorting algorithm.
·
The second case of
rendering a same character in two different display forms is the dead consonant
ನ್. It is also written
in a second form as U+0CF5. Sorting
issue in regards to this case is also dealt with the same way as in the
previous case.
The zero width Non-Joiner at U+200C cannot be used
instead of (U+0CF5),as the same sequence
of characters appear both with Zero width Non-Joiner and with U+0CF5, the two
sequences representing two different syllables (conjuncts).
2.6.5 Sorting of Diacritic characters
Diacritic
characters formed using symbols located at 0CD1, 0CD2, 0CD3, 0CD4 and 0CF9 to
render accents to consonants, are considered to be equivalent to the corresponding
consonants for sorting purposes and hence the above procedure can be adopted in
such cases also.
The sorting issues mentioned above may have
multiple solutions. Similar issues might have been solved by different methods
in respect of other Indian languages. Hence, it is desirable to evolve uniform
procedures for issues common to all Indian languages. However, solutions for
sorting problems mentioned here with respect Kannada have been obtained by
considering all consonants from U+0C95 to U+0CB9 and the consonant U+0CDE when
they appear independently in a data field as pure consonants (i.e. as two part
coded[Ex:0C95=(0C95,0CBB)]). The sorting of a data field is achieved by the
indexing method. All these can be elaborated to give the actual algorithms and
floe charts, if need be.
References:
1. “South and South East Asian Scripts”, Chapter 9 of The
Unicode Standard (Version 3.0), http://www.unicode.org/
2. “Creating and Supporting Open Type Fonts for Indic
Scripts”, http://www.microsoft.com/typography
3. “Unicode for Kannada Script” (written by Dr. CV Srinatha
Sastry), Directorate of Information Technology, Government of Karnataka
4. “User-Friendly Keyboard Layout for Kannada”, Kannada
Ganaka Parishat
5. “Standards for Kannada in Computers prescribed by the
Government of Karnataka”, Kannada Ganaka Parishat.
Appendix – 1: Unicode Chart and Collation if the suggested deletion and relocation of characters
are not allowed
Below figure shows the Unicode Chart for Kannada if
deletion and relocation of Characters are not allowed
|
|
0C8 |
0C9 |
0CA |
0CB |
0CC |
0CD |
0CE |
0CF |
|
0 |
▓▓ |
ಐ |
ಠ |
ರ |
ೀ |
▓▓ |
ೠ |
▓▓ |
|
1 |
▓▓ |
▓▓ |
ಡ |
ಱ |
ು |
|
ೡ |
▓▓ |
|
2 |
ಂ |
ಒ |
ಢ |
ಲ |
ೂ |
|
▓▓ |
▓▓ |
|
3 |
ಃ |
ಓ |
ಣ |
ಳ |
ೃ |
|
▓▓ |
▓▓ |
|
4 |
▓▓ |
ಔ |
ತ |
▓▓ |
|
▓▓ |
▓▓ |
▓▓ |
|
5 |
ಅ |
ಕ |
ಥ |
ವ |
▓▓ |
ೕ |
▓▓ |
|
|
6 |
ಆ |
ಖ |
ದ |
ಶ |
ೆ |
ೖ |
0 |
▓▓ |
|
7 |
ಇ |
ಗ |
ಧ |
ಷ |
ೇ |
▓▓ |
೧ |
▓▓ |
|
8 |
ಈ |
ಘ |
ನ |
ಸ |
ೈ |
▓▓ |
೨ |
▓▓ |
|
9 |
ಉ |
ಙ |
▓▓ |
ಹ |
▓▓ |
▓▓ |
೩ |
|
|
A |
ಊ |
ಚ |
ಪ |
|
ೊ |
▓▓ |
೪ |
▓▓ |
|
B |
ಋ |
ಛ |
ಫ |
|
ೋ |
▓▓ |
೫ |
▓▓ |
|
C |
|
ಜ |
ಬ |
|
ೌ |
▓▓ |
೬ |
▓▓ |
|
D |
▓▓ |
ಝ |
ಭ |
|
್ |
▓▓ |
೭ |
▓▓ |
|
E |
ಎ |
ಞ |
ಮ |
ಾ |
▓▓ |
|
೮ |
▓▓ |
|
F |
ಏ |
ಟ |
ಯ |
ಿ |
▓▓ |
▓▓ |
೯ |
▓▓ |
Below figure shows the Collating sequence of Kannada Unicode characters, if
additions and relocations are not allowed. The sequence is column wise, top to bottom
|
Column 1 |
Column 2 |
Column 3 |
Column 4 |
Column5 |
|
0C82 ಂ |
0CCD ್ |
0C96 ಖ |
0CA6 ದ |
0CB9 ಹ |
|
0C83 ಃ |
0CBB
|
0C97 ಗ |
0CA7 ಧ |
0CB3 ಳ |
|
0C85 ಅ |
0CBE ಾ |
0C98 ಘ |
0CA8 ನ |
0CB4
|
|
0C86 ಆ |
0CBF ಿ |
0C99 ಙ |
0CAA ಪ |
0CBC |
|
0C87 ಇ |
0CC0 ೀ |
0C9A ಚ |
0CAB ಫ |
|
|
0C88 ಈ |
0CC1 ು |
0C9B ಛ |
0CAC ಬ |
|
|
0C89 ಉ |
0CC2 ೂ |
0C9C ಜ |
0CAD ಭ |
|
|
0C8A ಊ |
0CC3 ೃ |
0C9D ಝ |
0CAE ಮ |
|
|
0C8B ಋ |
0CC4 ೄ |
0C9E ಞ |
0CAF ಯ |
|
|
0CE0 ೠ |
0CC6 ೆ |
0C9F ಟ |
0CB0 ರ |
|
|
0C8E ಎ |
0CC7 ೇ |
0CA0 ಠ |
0CB1 ಱ |
|
|
0C8F ಏ |
0CC8 ೈ |
0CA1 ಡ |
0CB2 ಲ |
|
|
0C90 ಐ |
0CCA ೊ |
0CA2 ಢ |
0CB5 ವ |
|
|
0C92 ಒ |
0CCB ೋ |
0CA3 ಣ |
0CB6 ಶ |
|
|
0C93 ಓ |
0CCC ೌ |
0CA4 ತ |
0CB7 ಷ |
|
|
0C94 ಔ |
0C95 ಕ |
0CA5 ಥ |
0CB8 ಸ |
|
Appendix – 2: Unicode Chart and
Collation if the suggested deletion and relocation of characters are allowed
Below
figure shows the Unicode Chart for Kannada if deletion and relocation of
Characters are allowed
|
|
0C8 |
0C9 |
0CA |
0CB |
0CC |
0CD |
0CE |
0CF |
|
0 |
▓▓ |
ಐ |
ಠ |
ರ |
ೀ |
▓▓ |
ೠ |
▓▓ |
|
1 |
▓▓ |
▓▓ |
ಡ |
ಱ |
ು |
|
▓▓ |
▓▓ |
|
2 |
ಂ |
ಒ |
ಢ |
ಲ |
ೂ |
|
▓▓ |
▓▓ |
|
3 |
ಃ |
ಓ |
ಣ |
ಳ |
ೃ |
|
▓▓ |
▓▓ |
|
4 |
▓▓ |
ಔ |
ತ |
▓▓ |
|
▓▓ |
▓▓ |
▓▓ |
|
5 |
ಅ |
ಕ |
ಥ |
ವ |
▓▓ |
▓▓ |
▓▓ |
|
|
6 |
ಆ |
ಖ |
ದ |
ಶ |
ೆ |
▓▓ |
0 |
▓▓ |
|
7 |
ಇ |
ಗ |
ಧ |
ಷ |
ೇ |
▓▓ |
೧ |
▓▓ |
|
8 |
ಈ |
ಘ |
ನ |
ಸ |
ೈ |
▓▓ |
೨ |
▓▓ |
|
9 |
ಉ |
ಙ |
▓▓ |
ಹ |
▓▓ |
▓▓ |
೩ |
|
|
A |
ಊ |
ಚ |
ಪ |
|
ೊ |
▓▓ |
೪ |
▓▓ |
|
B |
ಋ |
ಛ |
ಫ |
|
ೋ |
▓▓ |
೫ |
▓▓ |
|
C |
▓▓ |
ಜ |
ಬ |
|
ೌ |
▓▓ |
೬ |
▓▓ |
|
D |
▓▓ |
ಝ |
ಭ |
|
್ |
▓▓ |
೭ |
▓▓ |
|
E |
ಎ |
ಞ |
ಮ |
ಾ |
▓▓ |
▓▓ |
೮ |
▓▓ |
|
F |
ಏ |
ಟ |
ಯ |
ಿ |
▓▓ |
▓▓ |
೯ |
▓▓ |
|
|
|
|
|
|
|
|
|
|
Below figure shows the Collating sequence of
Kannada Unicode characters, if additions and relocations are allowed. The
sequence is column wise, top to bottom.
|
Column
1 |
Column
2 |
Column
3 |
Column
4 |
Column5 |
|
0C82 ಂ |
0CCD ್ |
0C96 ಖ |
0CA6 ದ |
0CB9 ಹ |
|
0C83 ಃ |
0CBB
|
0C97 ಗ |
0CA7 ಧ |
0CB3 ಳ |
|
0C85 ಅ |
0CBE ಾ |
0C98 ಘ |
0CA8 ನ |
0CB4
|
|
0C86 ಆ |
0CBF ಿ |
0C99 ಙ |
0CAA ಪ |
0CBC |
|
0C87 ಇ |
0CC0 ೀ |
0C9A ಚ |
0CAB ಫ |
|
|
0C88 ಈ |
0CC1 ು |
0C9B ಛ |
0CAC ಬ |
|
|
0C89 ಉ |
0CC2 ೂ |
0C9C ಜ |
0CAD ಭ |
|
|
0C8A ಊ |
0CC3 ೃ |
0C9D ಝ |
0CAE ಮ |
|
|
0C8B ಋ |
0CC4 ೄ |
0C9E ಞ |
0CAF ಯ |
|
|
0CE0 ೠ |
0CC6 ೆ |
0C9F ಟ |
0CB0 ರ |
|
|
0C8E ಎ |
0CC7 ೇ |
0CA0 ಠ |
0CB1 ಱ |
|
|
0C8F ಏ |
0CC8 ೈ |
0CA1 ಡ |
0CB2 ಲ |
|
|
0C90 ಐ |
0CCA ೊ |
0CA2 ಢ |
0CB5 ವ |
|
|
0C92 ಒ |
0CCB ೋ |
0CA3 ಣ |
0CB6 ಶ |
|
|
0C93 ಓ |
0CCC ೌ |
0CA4 ತ |
0CB7 ಷ |
|
|
0C94 ಔ |
0C95 ಕ |
0CA5 ಥ |
0CB8 ಸ |
|
Appendix – 3: Output from FontLab displaying all glyphs in the glyph set standardised by
KGP
